
Insight In No Time
Schema On The Fly
ScopeDB is a database that runs directly on top of any commodity object storage. It is designed explicitly for data workloads with massive writes, any-scale analysis, and flexible schema.
WHY SCOPEDB
"The data flow of insights should be equal to transactions."
Compared with the existing cloud data stack, which has a complex pipeline consisting of data movement, stream processing, and a data warehouse, ScopeDB supports real-time ingestion directly from user applications, eliminating any intermediate steps. Users can query the data immediately after ingestion, without the need for hours or even T+1 latency.
ScopeDB employs a stateless design. It enables effortless scaling without manual data reconciliation or replication, fully leverages cloud elasticity. For example, a cluster can dynamically scale out for peak workload in no time, where performance gets unlimitedly improved as you add more resources, and scale in when the peak has passed, delivering thoroughly elasticity tailored to your needs.
Read our introductory blog for more details.

Key Features
Real-time Ingestion
ScopeDB handles massive ingestion requests with arbitrary nodes independently, without sharding or partition leaders. The cluster of nodes can dynamically scale to manage peak traffic efficiently.
Any-scale Analysis & Exploration
ScopeDB fully leverages cloud resources to ensure that businesses can obtain optimal performance support without increasing additional hardware investment, achieving more efficient business operations.

Optimal Storage Format
Unleash the benefits of the compact columnar data format, and dedicated compression algorithms depending on data types.
Various Exploration Methods
Get insights from the data via searching, aggregations, time-series analytics, etc.
Adaptive Indexes
Accelerate queries with equality indexes, range indexes, search indexes, object indexes, materialized indexes, and more.
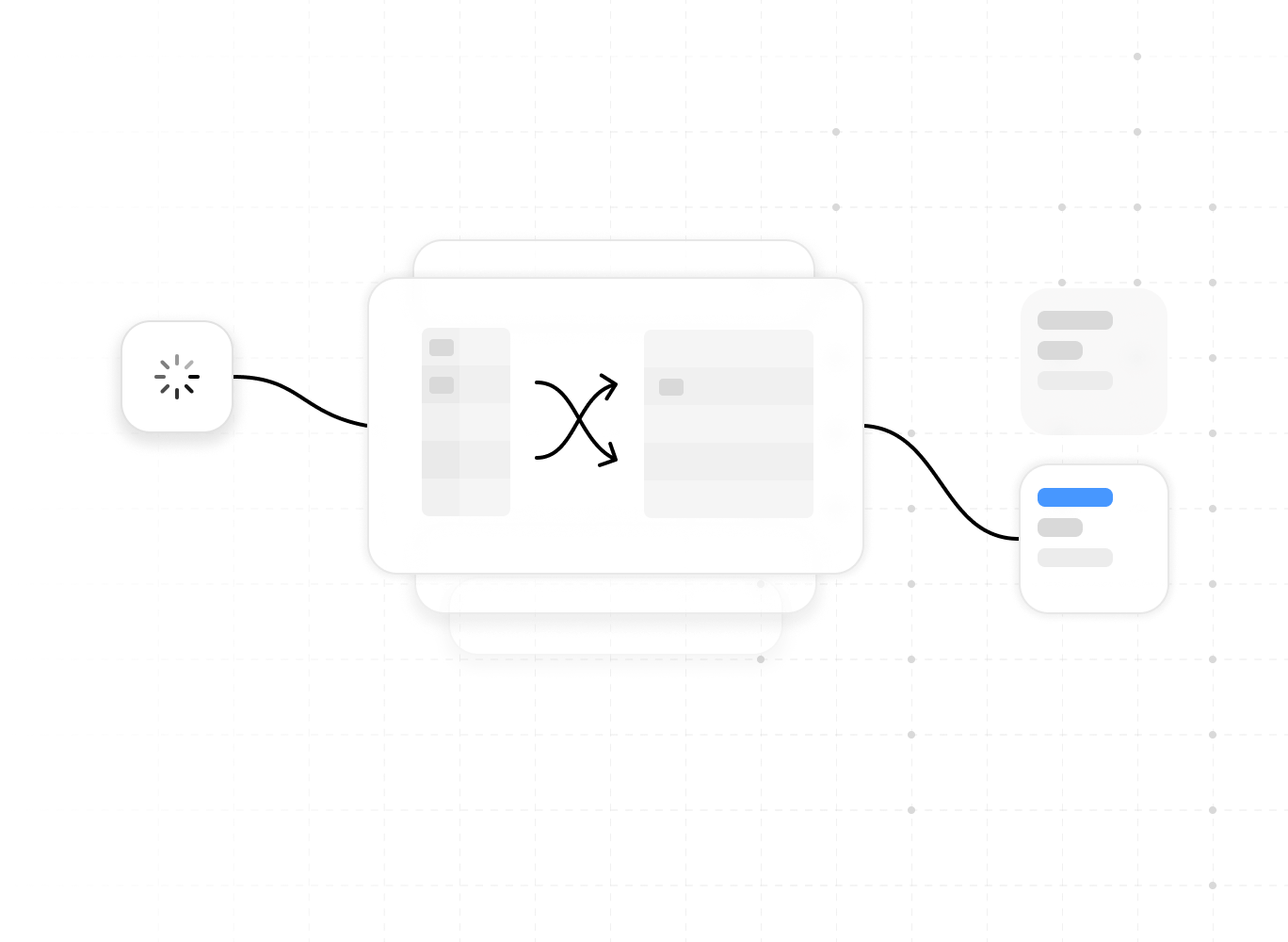
On-demand Resource Groups
Each group has its dedicated compute resources. All groups share the same object storage as the primary data backend.
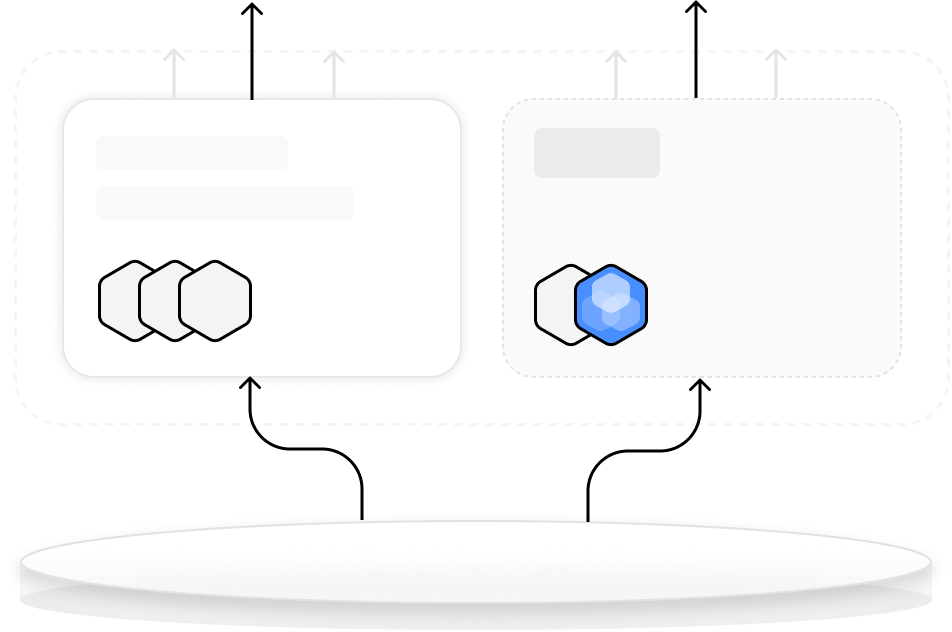
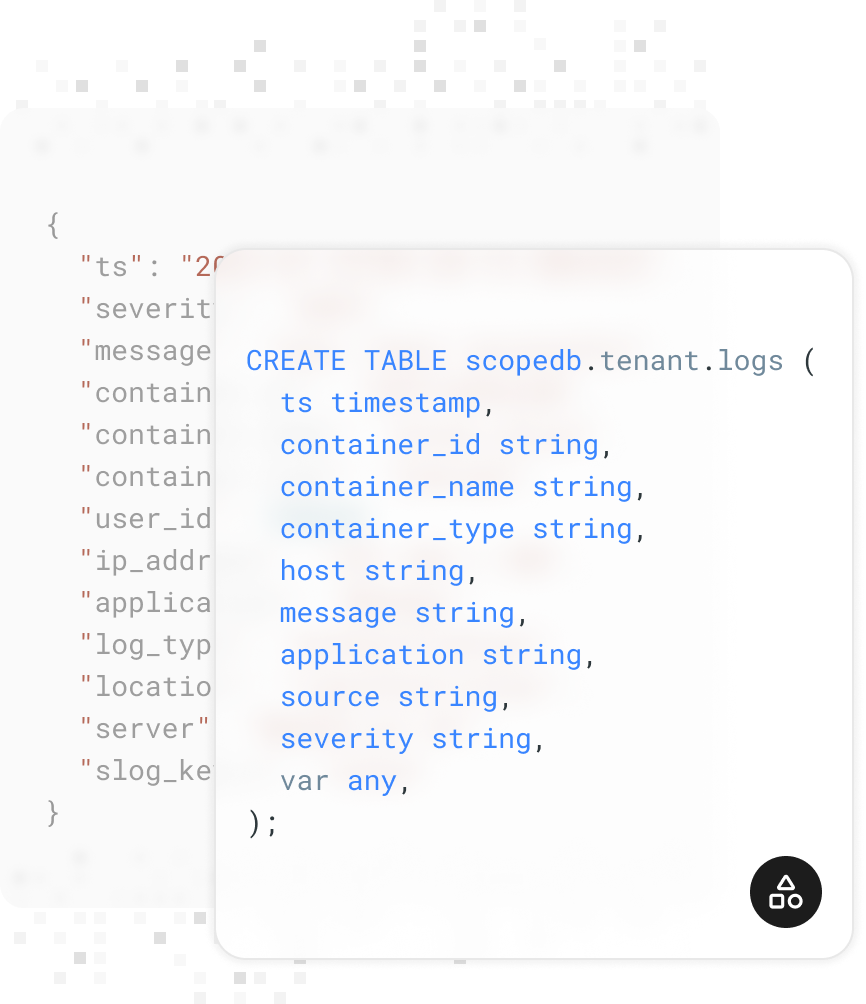
Flexible Data Schema
ScopeDB supports flexible data schema, enabling users to partially qualify schemas while storing additional data in an ANY column, allowing for efficient handling and analysis of semi-structured data.

Maximize the effectiveness of ScopeDB in various scenarios
Cloud Application Observability
Analyze application logs for complete visibility and accelerated troubleshooting. Unify scattered logs for processing and analysis to gain greater insights.
Real-time Behavior Analysis
Process millions of daily user interactions to power personalized recommendations and dynamic pricing for e-commerce platforms, or detect market manipulation and fraud patterns for social media.
Understand Your AI Agent Workflow
Capture the entire chat session with end-to-end visibility. See what your agent is doing step by step, and then improve latency and response quality with real-time insights.

ScopeQL Showcases
ScopeQL Is Not SQL 2.0
We reinvent the query language from relational algebra foundations with three radical simplifications:
Execution Flow
SQL's inside-out execution becomes ScopeQL's linear top-down pipeline.
Syntax Integrity
SQL's fragmented keywords become ScopeQL's orthogonal composability.
Compressible Expressions
SQL's subquery labyrinths become ScopeQL's native expressions reuse.
ScopeQL
SQL
Frequently asked questions
In which cloud platforms does ScopeDB work?
ScopeDB works on all major cloud platforms, including AWS, Azure, GCP, and more.
Explore More About
ScopeDB



Join the community
ScopeDB users share questions and best practices in our Discord community.
Join Discord